
Enterprises are well equipped to measure and manage the core transactional part of the business using structured data stored in conventional databases. However, managing the core transactional business is now merely a necessity and not sufficient to be competitive in today’s market.
With every business transaction today there is as an increasing volume of unstructured data such as documents, emails, sms messages, instant messages, log files such as web access logs, email logs etc. Enterprises are feeling the need to store, manage and analyze this unstructured data. However, conventional enterprise applications that excel at managing structured data are not really capable of handling the daunting size of such unstructured data, or even if they do, the cost of such infrastructure required can easily overtake the value added by managing such data.
Fortunately, there are new technologies that have evolved to help manage a combination of structured and unstructured data without requiring enterprises to squirm at the costs. If you consider the two primary determinants of costs involved in managing data:
– Storage Capacity
– Processing Capacity
Conventional technologies required you to plan the required storage and processing capacity in advance, so that you can provide for the worst case scenario of the maximum possible storage and peak processing capacity required through the lifetime of the data. It was not easy to dynamically scale up the costs proportional to actual capacity utilization.
This is where the new technologies like Cloud Computing and Big Data differ.
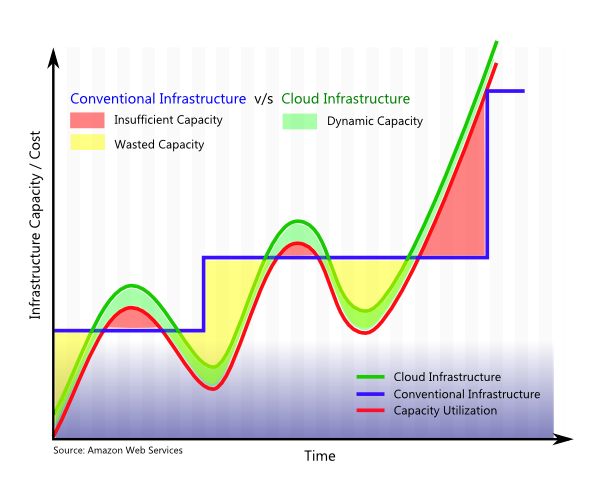
Cloud TCO
Cloud computing has made it easy for enterprises to dynamically scale up or down their infrastructure in small incremental steps, based on actual required storage and processing capacity. Big Data technologies complement this by providing data management software that can manage large volume of data at high speeds, by using a cluster of multiple low-capacity servers. It does this by distributing the storage and processing of the data across the entire cluster efficiently.